
This article introduces how to configure Apache Solr as the full-text search backend for Dovecot. And on top of the recommended Solr configuration, a few tweaks are also applied to improve Chinese, Japanese, Korean, aka. CJK, support.
1. Environment
Ubuntu 18.04 LTS is used in this tutorial and at the time of writing, the latest Dovecot suite in the official repository is 2.2.33.2-1ubuntu4.5.
2. Prerequisites
3. Solr Configuration
Solr hasn’t got a DEB distribution but it can be easily set up via Docker. Before we fire it up though, a ‘core’ is needed to be created for Dovecot. If you come from a document-oriented database background, a ‘core’ is similar to a collection, but also holds some additional configurations, e.g. schema, language analysis settings and etc.
$ apt-get install dovecot-solr # check out https://github.com/docker-solr/docker-solr/tree/909a2f021231e4fa1a2ef7ea77885b1530f80110 for details $ docker pull solr:7 # currently the suggested version by Dovecot $ mkdir -p /srv/solr # this is where we are going to store the data $ chown 8983:8983 $_ # update UID/GID to make sure Solr can write to it later $ docker run --rm -it -v /srv/solr:/var/solr -e SOLR_HOME=/var/solr -e INIT_SOLR_HOME=yes solr:7 bash # in container $ init-solr-home $ precreate-core dovecot # you can change the core name $ exit # in host $ cd /srv/solr/dovecot/conf $ rm -f schema.xml managed-schema solrconfig.xml
We now want to put our own version of solrconfig.xml and schema.xml in place. Later after Solr is booted up, managed-schema will be generated based on schema.xml and the latter will be renamed to schema.xml.bak.
(Click to view or download the files.)
<?xml version="1.0" encoding="UTF-8" ?>
<!-- This is the default config with stuff non-essential to Dovecot removed. -->
<config>
<!-- Controls what version of Lucene various components of Solr
adhere to. Generally, you want to use the latest version to
get all bug fixes and improvements. It is highly recommended
that you fully re-index after changing this setting as it can
affect both how text is indexed and queried.
-->
<luceneMatchVersion>7.7.0</luceneMatchVersion>
<!-- A 'dir' option by itself adds any files found in the directory
to the classpath, this is useful for including all jars in a
directory.
When a 'regex' is specified in addition to a 'dir', only the
files in that directory which completely match the regex
(anchored on both ends) will be included.
If a 'dir' option (with or without a regex) is used and nothing
is found that matches, a warning will be logged.
The examples below can be used to load some solr-contribs along
with their external dependencies.
-->
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-velocity-\d.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/analysis-extras/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/analysis-extras/lucene-libs" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-analysis-extras-\d.*\.jar" />
<!-- Data Directory
Used to specify an alternate directory to hold all index data
other than the default ./data under the Solr home. If
replication is in use, this should match the replication
configuration.
-->
<dataDir>${solr.data.dir:}</dataDir>
<!-- The default high-performance update handler -->
<updateHandler class="solr.DirectUpdateHandler2">
<!-- Enables a transaction log, used for real-time get, durability, and
and solr cloud replica recovery. The log can grow as big as
uncommitted changes to the index, so use of a hard autoCommit
is recommended (see below).
"dir" - the target directory for transaction logs, defaults to the
solr data directory.
"numVersionBuckets" - sets the number of buckets used to keep
track of max version values when checking for re-ordered
updates; increase this value to reduce the cost of
synchronizing access to version buckets during high-volume
indexing, this requires 8 bytes (long) * numVersionBuckets
of heap space per Solr core.
-->
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
<int name="numVersionBuckets">${solr.ulog.numVersionBuckets:65536}</int>
</updateLog>
<!-- AutoCommit
Perform a hard commit automatically under certain conditions.
Instead of enabling autoCommit, consider using "commitWithin"
when adding documents.
http://wiki.apache.org/solr/UpdateXmlMessages
maxDocs - Maximum number of documents to add since the last
commit before automatically triggering a new commit.
maxTime - Maximum amount of time in ms that is allowed to pass
since a document was added before automatically
triggering a new commit.
openSearcher - if false, the commit causes recent index changes
to be flushed to stable storage, but does not cause a new
searcher to be opened to make those changes visible.
If the updateLog is enabled, then it's highly recommended to
have some sort of hard autoCommit to limit the log size.
-->
<autoCommit>
<maxTime>${solr.autoCommit.maxTime:15000}</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
<!-- softAutoCommit is like autoCommit except it causes a
'soft' commit which only ensures that changes are visible
but does not ensure that data is synced to disk. This is
faster and more near-realtime friendly than a hard commit.
-->
<autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:1000}</maxTime>
</autoSoftCommit>
<!-- Update Related Event Listeners
Various IndexWriter related events can trigger Listeners to
take actions.
postCommit - fired after every commit or optimize command
postOptimize - fired after every optimize command
-->
</updateHandler>
<!-- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Query section - these settings control query time things like caches
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ -->
<query>
<!-- Solr Internal Query Caches
There are two implementations of cache available for Solr,
LRUCache, based on a synchronized LinkedHashMap, and
FastLRUCache, based on a ConcurrentHashMap.
FastLRUCache has faster gets and slower puts in single
threaded operation and thus is generally faster than LRUCache
when the hit ratio of the cache is high (> 75%), and may be
faster under other scenarios on multi-cpu systems.
-->
<!-- Filter Cache
Cache used by SolrIndexSearcher for filters (DocSets),
unordered sets of *all* documents that match a query. When a
new searcher is opened, its caches may be prepopulated or
"autowarmed" using data from caches in the old searcher.
autowarmCount is the number of items to prepopulate. For
LRUCache, the autowarmed items will be the most recently
accessed items.
Parameters:
class - the SolrCache implementation LRUCache or
(LRUCache or FastLRUCache)
size - the maximum number of entries in the cache
initialSize - the initial capacity (number of entries) of
the cache. (see java.util.HashMap)
autowarmCount - the number of entries to prepopulate from
and old cache.
maxRamMB - the maximum amount of RAM (in MB) that this cache is allowed
to occupy. Note that when this option is specified, the size
and initialSize parameters are ignored.
-->
<filterCache class="solr.FastLRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<!-- Query Result Cache
Caches results of searches - ordered lists of document ids
(DocList) based on a query, a sort, and the range of documents requested.
Additional supported parameter by LRUCache:
maxRamMB - the maximum amount of RAM (in MB) that this cache is allowed
to occupy
-->
<queryResultCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<!-- Document Cache
Caches Lucene Document objects (the stored fields for each
document). Since Lucene internal document ids are transient,
this cache will not be autowarmed.
-->
<documentCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<!-- custom cache currently used by block join -->
<cache name="perSegFilter"
class="solr.search.LRUCache"
size="10"
initialSize="0"
autowarmCount="10"
regenerator="solr.NoOpRegenerator" />
<!-- Lazy Field Loading
If true, stored fields that are not requested will be loaded
lazily. This can result in a significant speed improvement
if the usual case is to not load all stored fields,
especially if the skipped fields are large compressed text
fields.
-->
<enableLazyFieldLoading>true</enableLazyFieldLoading>
<!-- Result Window Size
An optimization for use with the queryResultCache. When a search
is requested, a superset of the requested number of document ids
are collected. For example, if a search for a particular query
requests matching documents 10 through 19, and queryWindowSize is 50,
then documents 0 through 49 will be collected and cached. Any further
requests in that range can be satisfied via the cache.
-->
<queryResultWindowSize>20</queryResultWindowSize>
<!-- Maximum number of documents to cache for any entry in the
queryResultCache.
-->
<queryResultMaxDocsCached>200</queryResultMaxDocsCached>
<!-- Use Cold Searcher
If a search request comes in and there is no current
registered searcher, then immediately register the still
warming searcher and use it. If "false" then all requests
will block until the first searcher is done warming.
-->
<useColdSearcher>false</useColdSearcher>
</query>
<!-- Request Dispatcher
This section contains instructions for how the SolrDispatchFilter
should behave when processing requests for this SolrCore.
-->
<requestDispatcher>
<httpCaching never304="true" />
</requestDispatcher>
<!-- Request Handlers
http://wiki.apache.org/solr/SolrRequestHandler
Incoming queries will be dispatched to a specific handler by name
based on the path specified in the request.
If a Request Handler is declared with startup="lazy", then it will
not be initialized until the first request that uses it.
-->
<!-- SearchHandler
http://wiki.apache.org/solr/SearchHandler
For processing Search Queries, the primary Request Handler
provided with Solr is "SearchHandler" It delegates to a sequent
of SearchComponents (see below) and supports distributed
queries across multiple shards
-->
<requestHandler name="/select" class="solr.SearchHandler">
<!-- default values for query parameters can be specified, these
will be overridden by parameters in the request
-->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
</lst>
</requestHandler>
<initParams path="/select">
<lst name="defaults">
<str name="df">_text_</str>
</lst>
</initParams>
<initParams path="/update/**">
<lst name="defaults">
<str name="df">_text_</str>
<str name="update.chain">remove_body_html</str>
</lst>
</initParams>
<!-- Response Writers
http://wiki.apache.org/solr/QueryResponseWriter
Request responses will be written using the writer specified by
the 'wt' request parameter matching the name of a registered
writer.
The "default" writer is the default and will be used if 'wt' is
not specified in the request.
-->
<queryResponseWriter name="xml"
default="true"
class="solr.XMLResponseWriter" />
<!-- Chains -->
<updateRequestProcessorChain name="remove_body_html">
<processor class="solr.HTMLStripFieldUpdateProcessorFactory">
<str name="fieldName">body</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>
</config>
<?xml version="1.0" encoding="UTF-8"?>
<schema name="dovecot" version="2.0">
<fieldType name="string" class="solr.StrField" omitNorms="true" sortMissingLast="true"/>
<fieldType name="long" class="solr.LongPointField" positionIncrementGap="0"/>
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="text" class="solr.TextField" autoGeneratePhraseQueries="true" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.StopFilterFactory" words="org/apache/lucene/analysis/cn/smart/stopwords.txt"/>
<filter class="solr.CJKBigramFilterFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="1" splitOnCaseChange="1" generateWordParts="1" splitOnNumerics="1" catenateAll="1" catenateWords="1"/>
<filter class="solr.FlattenGraphFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.FlattenGraphFilterFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.StopFilterFactory" words="org/apache/lucene/analysis/cn/smart/stopwords.txt"/>
<filter class="solr.CJKBigramFilterFactory"/>
<filter class="solr.WordDelimiterGraphFilterFactory" catenateNumbers="1" generateNumberParts="1" splitOnCaseChange="1" generateWordParts="1" splitOnNumerics="1" catenateAll="1" catenateWords="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<field name="id" type="string" indexed="true" required="true" stored="true"/>
<field name="uid" type="long" indexed="true" required="true" stored="true"/>
<field name="box" type="string" indexed="true" required="true" stored="true"/>
<field name="user" type="string" indexed="true" required="true" stored="true"/>
<field name="hdr" type="text" indexed="true" stored="false"/>
<field name="body" type="text" indexed="true" stored="false"/>
<field name="from" type="text" indexed="true" stored="false"/>
<field name="to" type="text" indexed="true" stored="false"/>
<field name="cc" type="text" indexed="true" stored="false"/>
<field name="bcc" type="text" indexed="true" stored="false"/>
<field name="subject" type="text" indexed="true" stored="false"/>
<!-- Used by Solr internally: -->
<field name="_version_" type="long" indexed="true" stored="true"/>
<uniqueKey>id</uniqueKey>
</schema>
The configurations provided above are slightly different from the ones provided in Dovecot Wiki mainly to improve CJK support. In a nutshell, my configuration
- Uses ICU Tokeniser instead of Standard Tokeniser
- Enables a few CJK-specific filters
- Uses HTML Strip Field Update Processor to remove HTML tags from email bodies
The configuration is obviously not perfect. While the ICU Tokeniser is an all-rounder when it comes to CJK languages, there are better solutions if we are talking about any specific one of them, e.g. HMM Chinese/Jieba for Chinese, Koromoji for Japanese, etc. In an ideal world we would like to first detect language during indexing and then query different language-specific fields based on query language. Sadly AFAIK this is not possible yet in Dovecot so the ICU Tokeniser is somewhat a compromise here to support all these languages. But for instance, if you only need to support English and Chinese, please do check out resources such as the Language Analysis section in Solr Ref Guide and Solr + Jieba Tokenisation. But anyway, thankfully we are not trying to build a full-blown search engine here and it’s usually sufficient for emails based on my testing.
Now the configuration of Solr is done, we can finally launch it and run a few tests:
# Solr can be quite memory-intensive, please adjust --memory/-m below to make sure it doesn't feast on all your resources
$ docker run -d --name solr --restart unless-stopped \
--log-driver json-file --log-opt max-size=10m --log-opt max-file=3 \
-m 2G -v /srv/solr:/var/solr \
-e SOLR_HOME=/var/solr \
-p 127.0.0.1:8983:8983 \ # and of course change the listen address if Dovecot is not on the same machine
solr:7
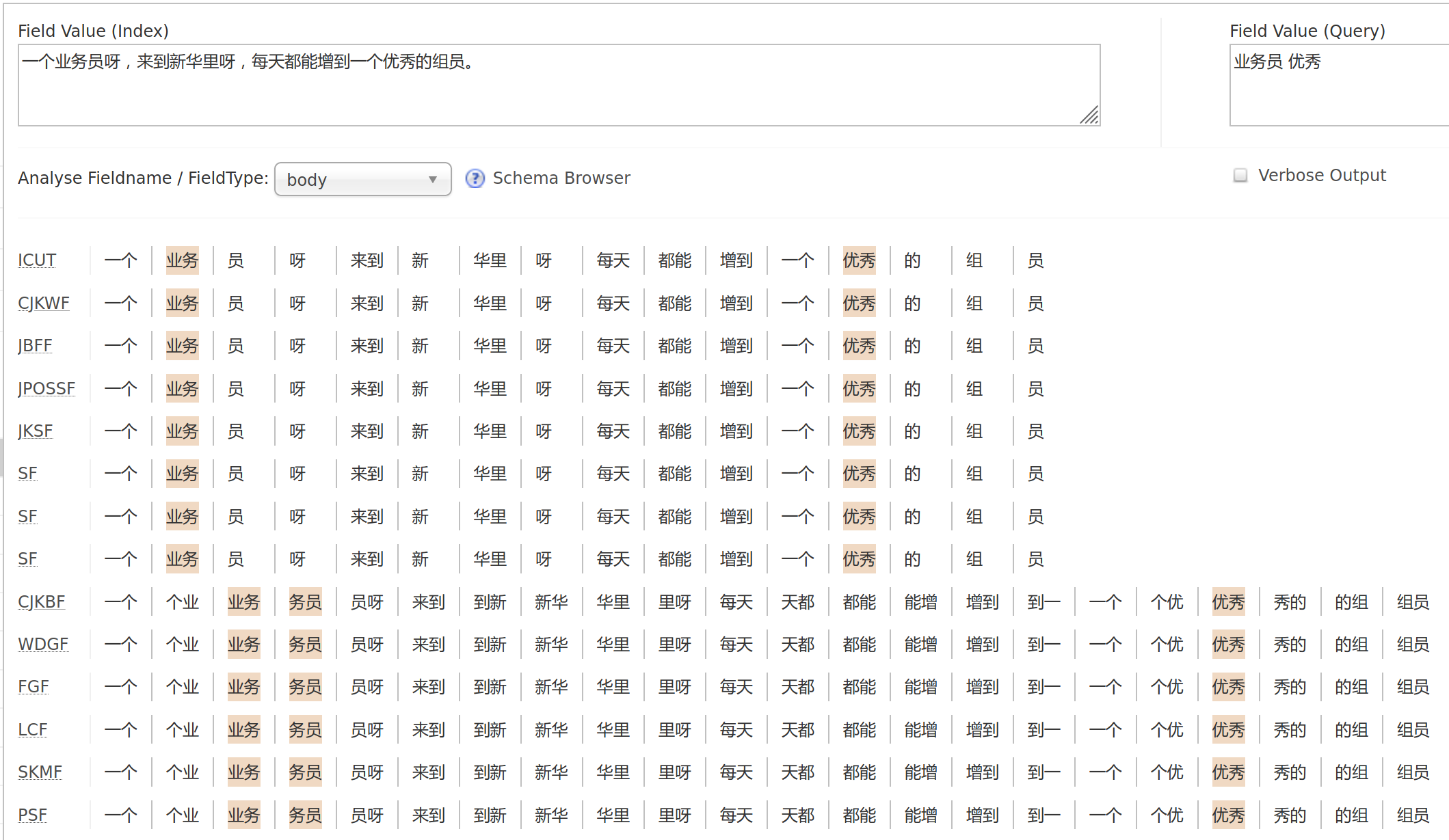
Open a browser and navigate to http://localhost:8983/solr/#/dovecot/analysis. Here we can run some sample texts through the indexer and make sure it works correctly before actually piping data into Solr.
For example,
(Chinese)
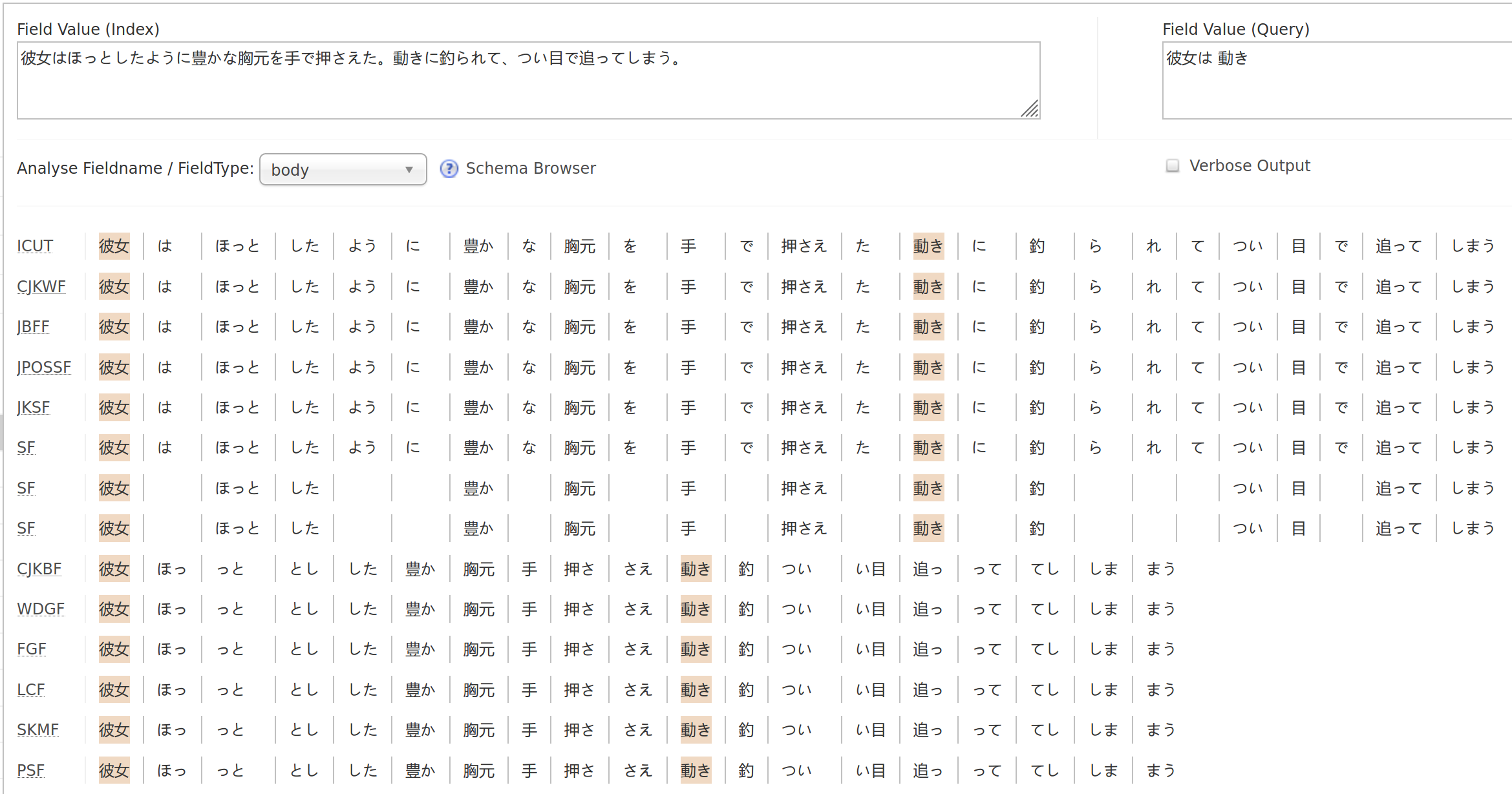
(Japanese, excerpted from ビブリア古書堂の事件手帖)
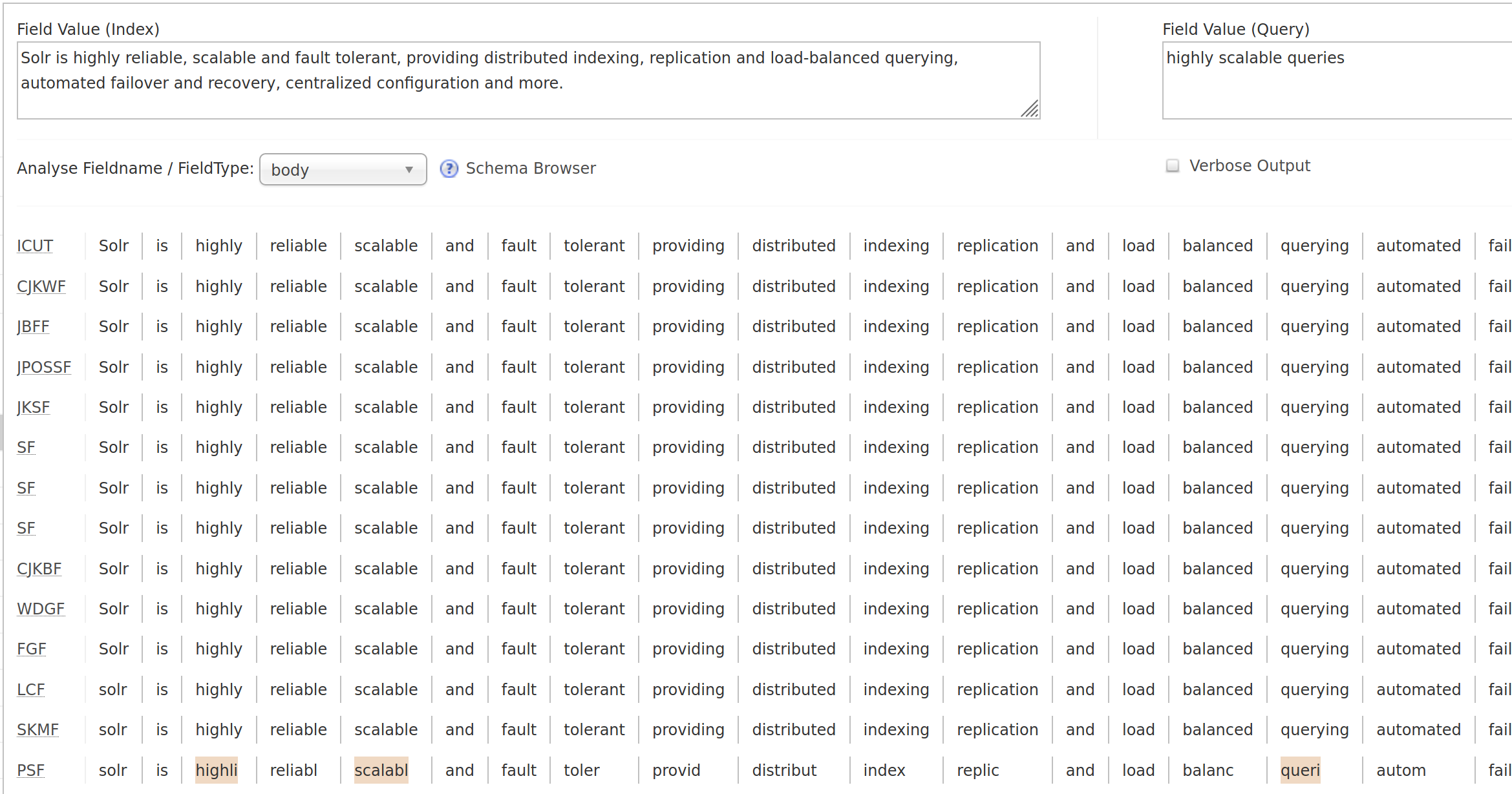
(English)
4. Dovecot Configuration
Configuration of Dovecot is quite straightforward and the Dovecot Wiki pretty much gets it covered.
In short, you should add
mail_plugins = $mail_plugins fts fts_solr
…to /etc/dovecot/conf.d/10-mail.conf and
plugin {
fts = solr
# Fall back to built in search.
#fts_enforced = no
fts_solr = url=http://127.0.0.1:8983/solr/dovecot/
# Detected languages. Languages that are not recognized, default to the
# first enumerated language, i.e. en.
fts_languages = en
# This chain of filters first normalizes and lower cases the text, then
# stems the words and lastly removes stopwords.
fts_filters = normalizer-icu snowball stopwords
# This chain of filters will first lowercase all text, stem the words,
# remove possessive suffixes, and remove stopwords.
fts_filters_en = lowercase snowball english-possessive stopwords
# These tokenizers will preserve addresses as complete search tokens, but
# otherwise tokenize the text into "words".
fts_tokenizers = generic email-address
fts_tokenizer_generic = algorithm=simple
# Proactively index mail as it is delivered or appended, not only when
# searching.
fts_autoindex=yes
# How many \Recent flagged mails a mailbox is allowed to have, before it
# is not autoindexed.
# This setting can be used to exclude mailboxes that are seldom accessed
# from automatic indexing.
fts_autoindex_max_recent_msgs=99
# Exclude mailboxes we do not wish to index automatically.
# These will be indexed on demand, if they are used in a search.
fts_autoindex_exclude = \Junk
fts_autoindex_exclude2 = \Trash
fts_autoindex_exclude3 = .DUMPSTER
}
…to /etc/dovecot/conf.d/90-plugin.conf and you are good to go. In case you are on Dovecot 2.3.6 or later, there are few more available dovecot-solr options which you can confirm their usages in the wiki.
And finally, if you want to pre-index several folders, e.g. inbox and sent, for your users, you can run (otherwise folders will be indexed on-demand):
# you may want to adjust the user/group here to match your auth-userdb/user permissions # and it's the same commands if you ever want to change Solr configurations and re-index emails $ sudo -u vmail -g mail doveadm -v fts rescan -A $ sudo -u vmail -g mail doveadm -v index -A -q INBOX $ sudo -u vmail -g mail doveadm -v index -A -q Sent
That’s it! You can now open your favourite email client and experience the fast full-text searching. And oh baby, it’s not only fast, it’s very fast XD